
Occupation Du Sol: Comment Cela Fonctionne À EOSDA
La classification de l’utilisation et de l’occupation des sols (LULC) est un type de données géospatiales dans un format visuel qui classe la surface de la Terre en classes distinctes telles que la forêt, l’eau, les cultures, etc. L’utilisation de la télédétection et des données géospatiales pour la détection des changements de couverture terrestre permet d’évaluer la dynamique de l’utilisation des terres ou d’évaluer comment le changement climatique modifie la surface de la Terre dans des régions spécifiques. Cela aide également à trouver des solutions basées sur les données concernant les infrastructures, telles que l’endroit où construire des routes, de nouveaux bâtiments ou des usines.
Les images satellites fournissent des données abondantes non seulement dans le spectre visible (RGB) mais aussi dans des gammes multispectrales imperceptibles pour l’homme. Une image satellite multispectrale est suffisante pour distinguer, par exemple, certaines cultures les unes des autres avec une plus grande précision que si l’on regardait une photo ordinaire. Cependant, pour réussir une classification LULC, vous devez former un modèle de réseau neuronal personnalisé.
Les clients d’EOS Data Analytics démontrent une demande croissante pour de tels modèles. Jetez un coup d’œil à la manière dont ces modèles sont formés avec cet aperçu et trois cas d’utilisation en Bulgarie, au Nigeria et au Brésil.
Pourquoi Les Entreprises Commandent La Classification De La Couverture Terrestre
Si vous débutez dans l’analyse géospatiale, vous vous demandez peut-être pourquoi les entreprises commandent de plus en plus la classification LULC. Vous pouvez regarder une image satellite RGB et identifier ce qui est quoi de vos propres yeux. Pourquoi optent-ils pour des images tramées à code couleur de la forêt s’ils ont déjà vu la forêt en RGB?
La réponse est évidente: évaluation quantitative. Les entreprises doivent traduire la dynamique du changement en chiffres, sinon elles ne seront pas en mesure de gérer l’utilisation des terres. Ils veulent prédire la quantité d’un produit final qu’ils peuvent produire et vendre en fonction du rendement des cultures, allouer le budget nécessaire et proposer des solutions d’ingénierie, de logistique, etc. pertinentes. Pendant ce temps, la représentation visuelle d’une classification LULC en couleurs simples sur une carte géographique aide les humains à comprendre les informations sur les résultats de la classification. Certains modèles que vous ne pouvez voir que lorsque vous visualisez les données et les analysez du point de vue d’un humain, en y ajoutant votre intuition, vos souvenirs et perceptions individuels, et des modèles logiques non linéaires que même la machine la plus intelligente n’aurait jamais devinés.
Il est essentiel de toujours affiner la précision des algorithmes de cartographie LULC car l’occupation du sol est une valeur très fluctuante – elle ne reste jamais la même. Les saisons changent, les niveaux d’eau vont et viennent, les pluies tombent, etc. Ainsi, un réseau de neurones doit continuellement s’adapter aux nouvelles circonstances et à leurs connexions les unes avec les autres
Par exemple, si vous avez affaire à une crue printanière sur une surface plane, comment savez-vous où va l’eau cette fois-ci ? C’est comme renverser un verre d’eau sur une table – la trajectoire du résultat est globalement compréhensible mais un peu incertaine, selon la texture et la taille de votre table, la vitesse à laquelle vous renversez le verre, les objets dessus, etc. De même, le flux d’inondation peut littéralement aller n’importe où, mais il a des dépendances qui sont presque impossibles à prédire avec le cerveau humain car il y a tellement de variables changeantes avec différents niveaux de corrélation. C’est là que l’IA entre en jeu.
L’équipe de scientifiques de l’EOSDA travaille en permanence sur la formation de modèles de réseaux neuronaux pour la classification de la couverture terrestre. Pour maintenir la plus grande précision, nous avons développé un modèle de régression personnalisé entièrement connecté (FCRM). Voyons comment cela fonctionne et passons en revue quelques exemples marquants où notre algorithme a obtenu d’excellents résultats.
Classification De L’occupation Du Sol: Comment Nous Procédons
1. Collecte et prétraitement des données: Tout d’abord, nous recueillons des images satellites et les données de vérité terrain correspondantes (telles que les conditions météorologiques ou les niveaux de précipitations) pour différentes classes de couverture terrestre. Nous prétraitons les données en créant une série chronologique pour la classification, en segmentant les images en patchs et en codant les étiquettes de vérité terrain.
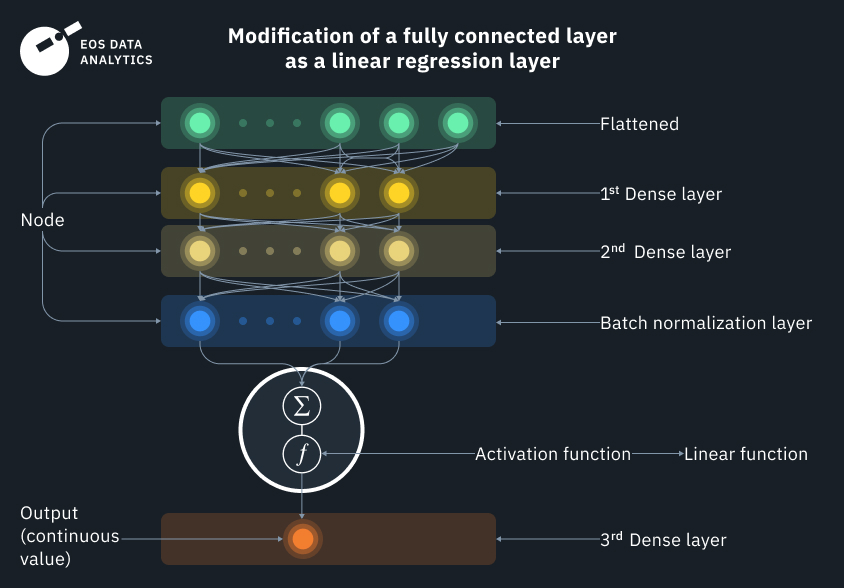
2. Conception de l’architecture: à ce stade, nous codons un modèle de régression entièrement connecté (FCRM) personnalisé pour chaque classe, qui est modifié en une régression linéaire sur la sortie. Tous ces termes peuvent vous sembler étrangers si vous n’avez jamais eu affaire à des réseaux de neurones auparavant, mais en réalité, ils sont plus simples qu’il n’y paraît. Par exemple, entièrement connecté signifie que toutes les entrées et tous les nœuds (couches) ont des connexions les uns avec les autres, alors que la régression linéaire la plus simple peut être décrite comme une équation linéaire sous forme d’interception de pente,
que nous avons tous étudié à l’école. Ici, x est une variable indépendante et y est une variable dépendante. Ils ont une dépendance linéaire, où chaque valeur de y dépend de la valeur de x.
Dans un réseau de neurones, vous pouvez considérer les données satellites (d’entrée) comme x et y, et la fonction elle-même comme un neurone. Tout comme les neurones physiques, les neurones fonctionnels ne se déclenchent que si une certaine condition est remplie
Dans notre algorithme, nous avons plusieurs neurones (fonctions) qui sont tous connectés les uns aux autres. En sortie, nous obtenons une fonction d’activation de régression linéaire prenant plusieurs régressions logistiques (binaires) en entrée, ce qui est une solution plutôt intéressante. Le modèle doit faire de nombreux choix multivariés avant de décider d’un résultat final. C’est comme une condition si exagérée pour chaque pixel dans lequel une image satellite se décompose, se transforme, puis se reconstitue, tout comme BumbleBee.
Les données de sortie continues montrent la probabilité que l’entrée initiale appartienne à une certaine classe. Donc, d’abord, nous obtenons la multitude de valeurs possibles, puis nous la divisons en plages qui montrent une mesure de la relation entre les variables d’entrée. Enfin, une certaine classe est donnée à une gamme choisie.
3. Fractionnement de l’ensemble de données: nous divisons l’ensemble de données prétraité en ensembles d’entraînement, de validation et de test en utilisant un ratio approprié (par exemple, 70 % d’entraînement, 15 % de validation et 15 % de test). Nous essayons également de nous assurer que tous les ensembles ont une représentation équilibrée des classes.
4. Entraînement des modèles: nous entraînons chaque FCRM séparément sur l’ensemble d’apprentissage en minimisant l’erreur quadratique moyenne (MSE) entre les probabilités prédites et les étiquettes de vérité terrain. Pendant la formation, nous utilisons des algorithmes d’optimisation pour mettre à jour les paramètres du modèle de manière itérative. Ensuite, nous régularisons les modèles pour éviter le surajustement (apprentissage sur le bruit) en utilisant des techniques comme le décrochage ou la décroissance du poids.
5. Surveillance des performances de validation: nous suivons les performances de chaque FCRM sur l’ensemble de validation pendant la formation à l’aide de mesures d’évaluation telles que le R au carré ou l’erreur absolue moyenne (MAE). Nous ajustons les hyperparamètres tels que le taux d’apprentissage, la taille des lots ou la complexité du modèle si nous devons optimiser les performances. Il n’y a généralement pas de solution unique pour tous ces paramètres, nous les ajustons donc à chaque fois.
6. Modélisation d’ensemble: nous combinons les prédictions des FCRM individuels pour obtenir une classification finale du type de couverture terrestre en employant des méthodes d’ensemble.
7. Évaluation des performances de l’ensemble de test: nous évaluons les performances globales de notre algorithme sur des données de test (auparavant invisibles pour un modèle) à l’aide de métriques telles que l’erreur statistique et la matrice de confusion.
8. Réglage fin et itération: à ce stade, nous parcourons les étapes 2 à 7, en affinant l’architecture, les hyperparamètres ou la méthode d’ensemble pour améliorer les performances de classification
9. Recadrage du résultat final par le cadre: enfin, nous préparons les visualisations de sortie par rapport aux coordonnées AOI (zone d’intérêt) prédéfinies.
Différence De Classification: Comparaison Entre EOSDA Et Sources De Référence
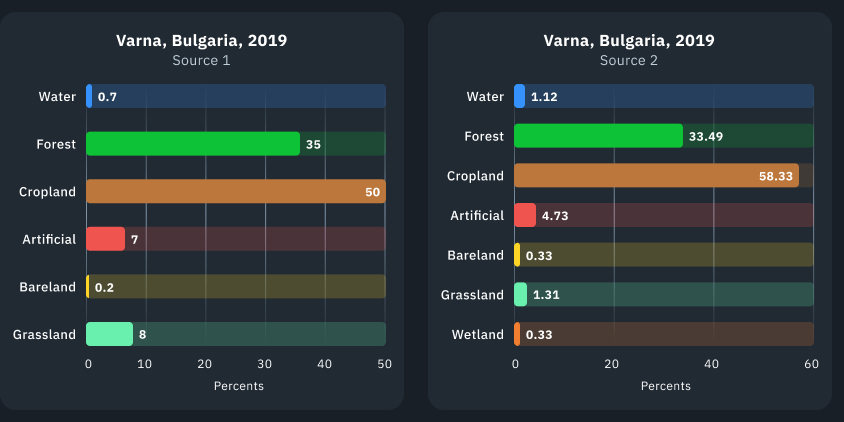
Nous avons comparé nos résultats de classification avec les données ouvertes LULC fournies par deux sources de référence pour valider la sortie générée par notre modèle. Appelons-les Source 1 et Source 2.
La Source 1 propose des données de 2017 à 2022, tandis que les données de la Source 2 vont de 2015 à 2019. Nous avons remarqué que les résultats de la classification LULC des grandes entreprises peuvent varier. Une des raisons possibles de ces divergences dans la classification de la couverture terrestre est les différentes méthodes d’agrégation des classes utilisées. Par exemple, un fournisseur de données peut classer les forêts dans une classe unique, tandis que le modèle d’un autre fournisseur fait la distinction entre les forêts clairsemées et denses. Par conséquent, les classes représentant des zones relativement petites dans le territoire d’intérêt peuvent présenter des différences significatives, comme le montre la visualisation ci-dessous. Toutefois, cela ne s’applique pas aux changements d’une année à l’autre au sein d’une même classe
Sur les visualisations et les graphiques, vous pouvez voir le territoire de la ville de Varna, en Bulgarie. Nous pouvons dire que les cours ne restent pas les mêmes, mais fluctuent un peu d’une année à l’autre. Les graphiques à barres ci-dessous montrent une ventilation plus détaillée de 2019 car elle est commune aux deux sources de référence.
La visualisation et le graphique à barres suivants montrent les statistiques reçues du modèle EOSDA. Comme vous pouvez le voir, les résultats de la classification sont un peu différents.
Un exemple frappant: la classification EOS Data Analytics LULC fournit la classe Grassland pour les zones de pâturage et les zones avec la présence d’arbustes trop petits, tandis que la classification Source 2 démontre que ces valeurs sont dans des classes complètement différentes. Pour cette raison, le pourcentage de classes peut différer.
Après la comparaison, nous avons conclu que les résultats de la classification de la couverture terrestre de différents modèles peuvent varier. Cela peut être dû au fait que des objets qui semblent visuellement similaires mais de nature différente peuvent être classés dans une classe ou une autre, en fonction de l’algorithme, des données d’entrée, du processus de formation, etc. Pour évaluer le niveau de précision avec le niveau de précision le plus élevé, nous aurions besoin d’analyser le cas d’utilisation particulier et les données de validation.

Exemples De Classification De L’occupation Du Sol Par EOSDA
Comme vous pouvez le voir dans la comparaison ci-dessus, les scientifiques de l’EOSDA ont pu atteindre un haut niveau de détail dans notre algorithme LULC. Essentiellement, le facteur qui aurait pu contribuer le plus était l’utilisation de courtes périodes de données satellitaires de séries chronologiques. Cette approche permet également d’avoir une vision plus fine des classes identifiées. Cependant, nous devons admettre que les données d’entrée doivent également être suffisantes.
Pour la validation plus poussée de notre modèle sur divers paysages et conditions climatiques, nous l’avons formé sur les données de quelques régions différentes. Jetez un œil aux exemples ci-dessous pour voir les résultats de la formation.
Région №1: Bulgarie, 2021
Zoom sur les résultats de classification LULC obtenus par le modèle EOS Data Analytics en Bulgarie. Ici, nous pouvons voir une identification très précise des classes de forêts, d’eau et de terres cultivées. Il convient de mentionner que ce dernier a des dépendances étroites entre le nombre d’images d’entrée obtenues, les fluctuations saisonnières et le résultat de sortie.
Comme nous pouvons le constater à partir du résultat de sortie, les scientifiques de l’EOSDA ont formé le modèle sur un nombre et une qualité suffisants de données d’entrée. La classe de terrain nu de couleur jaune comprend une fixation détaillée de l’infrastructure de chaussée locale. Le modèle a également identifié des objets artificiels.

Région №2: Nigéria, 2021
Ce résultat de formation montre que le modèle a identifié les terres arides du Nigéria comme une classe de terres nues. Néanmoins, une petite quantité d’eau et de prairies est également identifiée avec précision. Des territoires encore plus petits d’une classe de zones humides présentent des inondations saisonnières (ou leur absence, ce qui pourrait signifier une sécheresse).
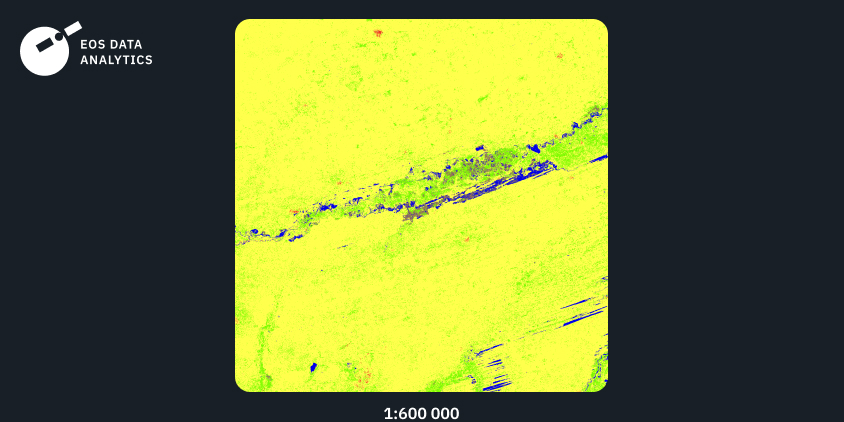
Région №3: Amérique Du Sud, 2021
Le troisième exemple montre la sortie de notre modèle formé sur les données d’entrée d’Amérique du Sud. Encore une fois, nous pouvons voir un haut niveau de détail combiné à des transitions fluides entre les classes. Alors que la classe des forêts est prédominante dans la Zone donnée, la classe des prairies se distingue précisément de la classe des forêts.
Réflexions Finales
Les entreprises de plusieurs domaines peuvent tirer parti de nos modèles pour obtenir des informations plus approfondies sur les modèles d’utilisation des terres, optimiser l’allocation des ressources et prendre des décisions éclairées pour augmenter la rentabilité. Dans une perspective plus large, en obtenant une classification pouce par pouce de l’occupation du sol des territoires d’intérêt, les collectivités peuvent prendre les mesures nécessaires pour sauver l’environnement et construire des infrastructures durables.
Chaque modèle formé sur mesure à EOSDA est basé sur un algorithme supervisé par des humains, c’est pourquoi nous sommes en mesure d’obtenir une qualité aussi remarquable des résultats de sortie. Comme point de départ, nous avons déjà entraîné notre modèle LULC sur les données de différentes zones géographiques, comme vous pouvez le voir dans cet article. En affinant davantage l’architecture et les paramètres de données dans chaque cas donné de manière itérative, nos scientifiques sont en mesure de réduire considérablement l’erreur statistique, c’est-à-dire d’augmenter la précision de la classification.
L’autre avantage est que plus nos scientifiques supervisent de modèles LULC personnalisés, plus ils ont de contexte à portée de main. En conséquence, ils peuvent construire des modèles plus intelligents que quelqu’un sans expérience dans ce domaine. Nous obtenons en permanence des informations précieuses sur la manière dont la surveillance par satellite contribue à la gestion efficace des ressources terrestres, ainsi qu’aux efforts de conservation de l’environnement et de la recherche des réponses aux changements climatiques.
À propos de l'auteur:
Rim Elijah est titulaire d'un double diplôme en administration des affaires et en sciences politiques de l'Université de Stockholm. En tant que Vice-présidente des ventes chez EOSDA, elle supervise tous les aspects du développement et de la mise en œuvre du modèle commercial ainsi que la croissance de la couverture mondiale de l’entreprise. Elle a établi avec succès un certain nombre de partenariats stratégiques mettant l'accent sur des solutions durables en Afrique et en Asie.
Derniers articles
Logiciel Agricole : Solutions Et Outils Prêts À L’Emploi
Logiciel agricole est le partenaire discret sur le champ qui travaille sans relâche dans les coulisses pour soutenir les agriculteurs pendant la formation des écosystèmes agricoles durables.

Indices De Végétation Pour L’Agriculture Numérique
Les indices de végétation permettent de surveiller la productivité des cultures, de détecter des stress environnementaux, de prévoir les rendements et d'optimiser les pratiques agricoles.

FANCAMPO Mexico Utilise Télédétection À Assurer Récolte
L'assurance agricole au Mexique passe à un niveau supérieur grâce au fonds FANCAMPO qui utilise l'analyse d'images satellitaires via EOSDA Crop Monitoring pour évaluer les demandes d’indemnisation.