Clasificación De La Cubierta Terrestre En EOSDA
La clasificación del uso y la cobertura del suelo (LULC – Land use and land cover) hace referencia a un tipo de datos geoespaciales, en formato visual, que clasifica la superficie terrestre en distintas clases como bosques, agua, cultivos, etc. La utilización de la teledetección y datos geoespaciales para la detección de cambios en la cubierta terrestre ayuda a monitorizar y evaluar la dinámica del uso de la tierra, así como a valorar cómo el cambio climático altera la superficie terrestre en regiones concretas. También ayuda a encontrar soluciones basadas en datos sobre infraestructuras, como dónde construir carreteras, nuevos edificios o plantas.
Las imágenes de satélite proporcionan abundantes datos, no sólo en el espectro visible (RGB), también en gamas multiespectrales imperceptibles para el ser humano. Una imagen de satélite multiespectral es suficiente para distinguir, por ejemplo, unos cultivos de otros con mayor precisión que si se observa una foto normal. Sin embargo, para realizar con éxito una clasificación LULC, sería necesario entrenar un modelo de red neuronal personalizado.
Los clientes de EOS Data Analytics muestran un creciente interés y demanda respecto a este tipo de modelos. Echemos un vistazo a cómo se entrenan estos modelos y tres casos de uso reales en Bulgaria, Nigeria y Brasil.
¿Por Qué Las Empresas Solicitan La Clasificación De La Cubierta Terrestre?
Si es usted nuevo en el análisis geoespacial, quizá se pregunte por qué las empresas encargan cada vez más la clasificación LULC. Puede mirar una imagen de satélite RGB e identificar qué es cada cosa con sus propios ojos. ¿Por qué recurren a imágenes ráster del bosque codificadas por colores si ya han visto el bosque en la imagen RGB?
La respuesta es: evaluación cuantitativa. Las empresas tienen que plasmar la dinámica del cambio en números, porque si no, no podrán gestionar el uso del suelo. Quieren predecir la cantidad de un producto final que pueden producir y vender en función del rendimiento de los cultivos, asignar el presupuesto necesario e idear las soluciones pertinentes de ingeniería, logística, etc. Mientras tanto, la representación visual de una clasificación LULC en colores simples sobre un mapa geográfico nos ayuda a comprender la información sobre los resultados de la clasificación. Algunos patrones sólo se pueden ver cuando se visualizan los datos y se analizan desde la perspectiva de un ser humano, incorporando a la mezcla su intuición, sus recuerdos y percepciones individuales, y patrones lógicos no lineales que ni siquiera la máquina más inteligente habría adivinado jamás.
Es esencial afinar la precisión de los algoritmos de cartografía LULC porque la cubierta terrestre es un valor muy fluctuante: nunca permanece igual. Las estaciones cambian, los niveles de agua van y vienen, la lluvia cae en mayor o menor medida, etcétera. Así que una red neuronal tiene que ajustarse continuamente a las nuevas circunstancias y a sus conexiones entre sí.
Por ejemplo, si se trata de una inundación primaveral en un terreno llano, ¿cómo saber adónde va el agua? Es como derramar un vaso de agua sobre una mesa: la trayectoria del resultado es en general comprensible, pero un poco incierta, dependiendo de la textura y el tamaño de la mesa, la velocidad a la que se gire el vaso, los objetos que haya sobre ella, etc. Del mismo modo, la corriente de la inundación puede ir literalmente a cualquier parte, pero tiene algunas dependencias que son casi imposibles de predecir con el cerebro humano porque hay muchas variables cambiantes con diferentes niveles de correlación. Ahí es donde entra en juego la IA.
El equipo de científicos de EOSDA trabaja continuamente en el entrenamiento de modelos de redes neuronales para la clasificación de la cubierta terrestre. Para mantener la máxima precisión, hemos desarrollado un modelo de regresión totalmente conectado (FCRM) personalizado. Veamos cómo funciona y repasemos algunos ejemplos destacados en los que nuestro algoritmo obtuvo grandes resultados.
Clasificación De La Cubierta Terrestre: Cómo Lo Hacemos
1. Recopilación y preprocesamiento de datos: En primer lugar, recopilamos imágenes de satélite y los correspondientes datos reales sobre el terreno (como el tiempo o los niveles de precipitaciones) para las distintas clases de cobertura del suelo. Preprocesamos los datos construyendo una serie temporal para la clasificación, segmentando las imágenes en parches y codificando las etiquetas de la verdad sobre el terreno.
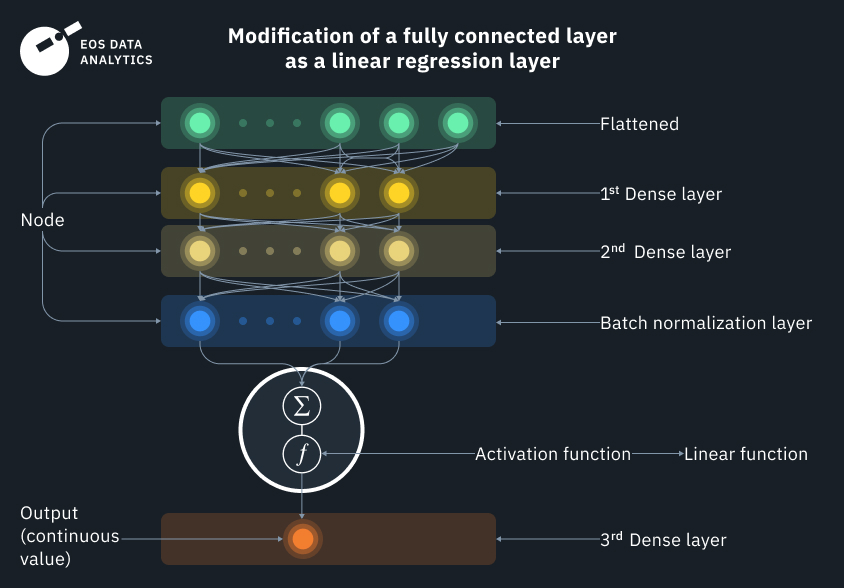
2. Diseño de la arquitectura: En esta fase, codificamos un modelo de regresión totalmente conectado (FCRM) personalizado para cada clase, que se modifica en una regresión lineal sobre la salida. Todos estos términos pueden sonarle extraños si no ha trabajado antes con redes neuronales, pero en realidad son más sencillos de lo que parecen. Por ejemplo, totalmente conectado significa que todas las entradas y todos los nodos (capas) tienen conexiones entre sí, mientras que la regresión lineal más sencilla puede describirse como una ecuación lineal en forma de pendiente-intersección,
que todos hemos estudiado en la escuela; x es una variable independiente e y es una variable dependiente. Tienen una dependencia lineal, en la que cada valor de y depende del valor de x.
En una red neuronal, se puede pensar en los datos de satélite (de entrada) como x e y, y en la propia función como una neurona. Al igual que las neuronas físicas, las neuronas de función sólo se disparan si se cumple una determinada condición.
En nuestro algoritmo tenemos varias neuronas (funciones) conectadas entre sí. En la salida, obtenemos una función de activación de regresión lineal que toma múltiples regresiones logísticas (binarias) como datos de entrada, lo que es una solución bastante ingeniosa. El modelo tiene que hacer muchas elecciones multivariantes antes de decidir el resultado final. Es como una condición if exagerada para cada píxel en el que una imagen de satélite se descompone, se transforma y luego se recompone, como BumbleBee en Transformers.
Los datos de salida continuos muestran la probabilidad de que la entrada inicial pertenezca a una determinada clase. Así, primero se obtiene la multitud de valores posibles, luego se divide en rangos que muestran una medida de la relación entre las variables de entrada. Por último, se asigna una determinada clase a un rango elegido.
3. División del conjunto de datos: Dividimos el conjunto de datos preprocesados en conjuntos de entrenamiento, validación y prueba utilizando una proporción adecuada (por ejemplo, 70% de entrenamiento, 15% de validación y 15% de prueba). También intentamos asegurarnos de que todos los conjuntos tengan una representación equilibrada de las clases.
4. Entrenamiento de los modelos: Entrenamos cada modelo de regresión por separado en el conjunto de entrenamiento minimizando el error cuadrático (MSE) entre las probabilidades predichas y las etiquetas reales. Durante el entrenamiento, utilizamos algoritmos de optimización para actualizar los parámetros del modelo de forma iterativa. A continuación, regularizamos los modelos para evitar el sobreajuste (aprendizaje con ruido) empleando técnicas como el dropout o el decaimiento del peso (weight decay).
5. Seguimiento del rendimiento de validación: Hacemos un seguimiento del rendimiento de cada modelo de regresión en el conjunto de validación durante el entrenamiento utilizando métricas de evaluación como R-cuadrado o error medio absoluto (MAE). Ajustamos hiperparámetros como la tasa de aprendizaje, el tamaño del lote o la complejidad del modelo si necesitamos optimizar el rendimiento. Normalmente no existe una solución única para todos estos parámetros, por lo que siempre los ajustamos con precisión.
6. Modelado conjunto: Combinamos las predicciones de los modelos de regresión individuales para obtener una clasificación final del tipo de cobertura del suelo, empleando métodos de conjunto.
7. Evaluación del rendimiento del conjunto de pruebas: Evaluamos el rendimiento global de nuestro algoritmo en datos de prueba (no vistos previamente por un modelo) utilizando métricas como el error estadístico y la matriz de confusión.
8. Ajuste e iteración: En esta etapa, iteramos sobre los pasos 2-7, refinando la arquitectura, los hiperparámetros o el método de modelado conjunto para mejorar el rendimiento de la clasificación.
9. Recorte del resultado final: Por último, preparamos los datos de salida a visualizar con respecto a las coordenadas predefinidas del área de interés.
Diferencias En La Clasificación: Comparación Entre EOSDA Y Las Fuentes De Referencia
Comparamos nuestros resultados de clasificación LULC con los datos abiertos proporcionados por dos fuentes de referencia, para validar el resultado generado por nuestro modelo. Llamemos a esas fuentes Fuente 1 y Fuente 2.
Fuente 1 ofrece datos de 2017 a 2022, mientras que los de Fuente 2 van de 2015 a 2019. Hemos observado que los resultados de la clasificación LULC de las grandes empresas pueden variar. Una posible razón de estas discrepancias en la clasificación de la cubierta terrestre son los diferentes métodos de agregación de clases empleados. Por ejemplo, un proveedor de datos puede clasificar los bosques como una única clase, mientras que el modelo de otro proveedor distingue entre bosques densos y con vegetación dispersa. Así pues, las clases que representan áreas relativamente pequeñas dentro del área de interés pueden presentar diferencias significativas, como se muestra a continuación. Sin embargo, esto no se aplica a los cambios interanuales dentro de la misma clase.
En las imágenes y gráficos, puede ver el territorio de la ciudad de Varna, Bulgaria. Por lo general, las clases no permanecen iguales, sino que fluctúan un poco de un año a otro. Los gráficos de barras siguientes muestran un desglose más detallado de 2019, ya que es común en ambas fuentes de referencia, demostrando también diferencias dentro de 2019.
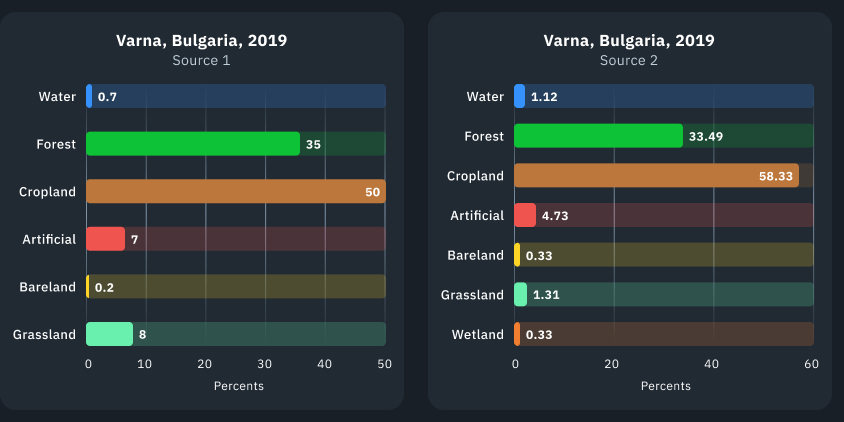
La siguiente representación y gráfico de barras muestra las estadísticas obtenidas del modelo EOSDA. Como puede verse, los resultados de la clasificación son un poco diferentes.
Un ejemplo llamativo: La clasificación LULC de EOS Data Analytics asigna la clase ‘Pastizal’, tanto a las zonas de pasto como a las zonas con presencia de arbustos de tamaño insuficiente, mientras que la clasificación de Fuente 2 demuestra que estos valores se encuentran en clases completamente diferentes. Por este motivo, el porcentaje de clases puede diferir.
Tras la comparación, llegamos a la conclusión de que los resultados de clasificación de la cubierta terrestre de distintos modelos pueden variar. Esto podría deberse al hecho de que objetos que parecen visualmente iguales, pero de naturaleza diferente, podrían clasificarse como una clase u otra, dependiendo del algoritmo, los datos de entrada, el proceso de entrenamiento, etc. Para evaluar el nivel de exactitud con el máximo nivel de precisión, habría que analizar el caso de uso concreto y los datos de validación de la verdad sobre el terreno.

Ejemplos De Clasificación De La Cubierta Terrestre De EOSDA
Como puede verse en la comparación anterior, los científicos de EOSDA fueron capaces de alcanzar un alto nivel de detalle en nuestro algoritmo LULC. En esencia, el factor que pudo contribuir más fue el uso de periodos cortos de datos de series temporales. Este enfoque también nos permite obtener una visión más nítida de las clases identificadas. Aunque debemos admitir que los datos de entrada también tienen que ser suficientes.
Para seguir validando nuestro modelo en distintos paisajes y condiciones climáticas, lo entrenamos con datos de algunas regiones diferentes. Eche un vistazo a los ejemplos siguientes para ver los resultados del entrenamiento.
Región 1: Bulgaria, 2021
Veamos los resultados de la clasificación LULC obtenidos por el modelo de EOS Data Analytics en Bulgaria. Aquí podemos ver una identificación muy precisa de las clases bosque, agua y tierras de cultivo. Merece la pena mencionar que esta última presenta una estrecha dependencia entre el número de imágenes usadas como datos de entrada, las fluctuaciones estacionales y el resultado de salida.
Como podemos deducir del resultado de salida, los científicos de EOSDA entrenaron el modelo con un número y una calidad suficientes de datos de entrada. La clase de terreno desnudo, de color amarillo, incluye de forma detallada la fijación de la infraestructura de pavimento local. El modelo también identificó objetos artificiales.

Región 2: Nigeria, 2021
Esta salida de entrenamiento muestra que el modelo identificó las tierras secas de Nigeria como una clase de tierra desnuda. No obstante, también se identifica una pequeña cantidad de agua y praderas con detallada precisión. Incluso territorios más pequeños de una clase de humedal muestran inundaciones estacionales (o ausencia de ellas, lo que podría significar una sequía).
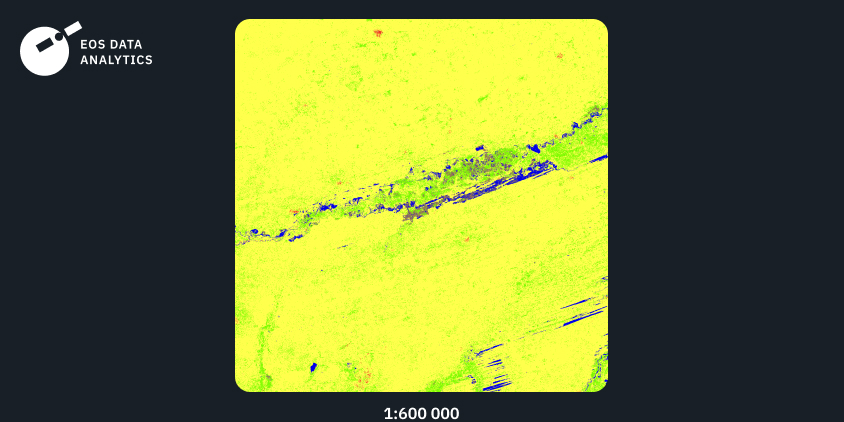
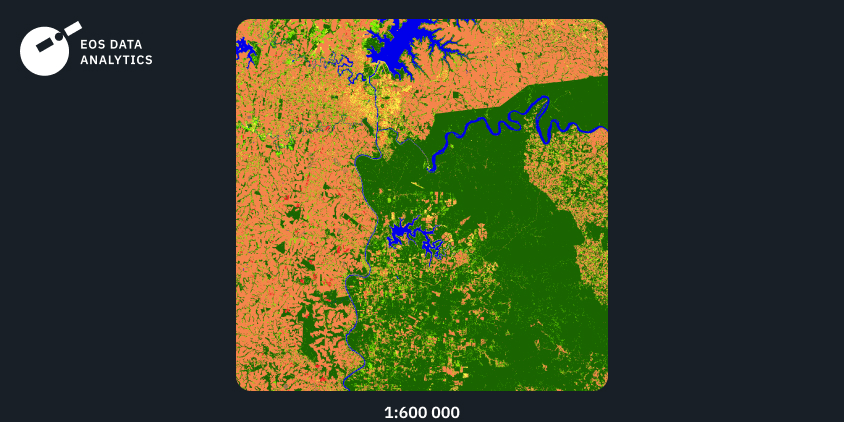
Región 3: Sudamérica, 2021
El tercer ejemplo muestra el resultado de nuestro modelo, entrenado con datos de entrada de Sudamérica. De nuevo, podemos ver un alto nivel de detalle combinado con transiciones suaves entre las clases. Mientras que la clase bosque predomina en el área de interés, la clase pradera se distingue con precisión respecto de la clase bosque.
Consideraciones Finales
Empresas de múltiples ámbitos pueden aprovechar nuestros modelos para conocer mejor los patrones de uso del suelo, optimizar la asignación de recursos y tomar mejores decisiones para aumentar la rentabilidad. Desde una perspectiva más amplia, al obtener una clasificación de la cubierta terrestre centímetro a centímetro de las áreas de interés, las comunidades pueden tomar las medidas necesarias para salvar el medioambiente y construir infraestructuras sostenibles.
Cada modelo entrenado a medida en EOSDA se basa en un algoritmo supervisado por humanos, por eso somos capaces de lograr una calidad tan sorprendente en los resultados de salida. Como punto de partida, ya hemos entrenado nuestro modelo LULC con datos de distintas zonas geográficas, como puede verse en este artículo. Afinando aún más la arquitectura y los parámetros de los datos en cada caso concreto de forma iterativa, nuestros científicos son capaces de lograr un error estadístico significativamente menor, es decir, aumentar la precisión de la clasificación.
Otra ventaja es que cuantos más modelos LULC personalizados supervisen nuestros científicos, más información contextual tendrán a mano. Como resultado, pueden construir modelos más inteligentes que alguien sin experiencia en este campo. Obtenemos información valiosa de forma continua sobre cómo la monitorización por satélite contribuye a una gestión eficaz de los recursos terrestres, junto con los esfuerzos de conservación del medioambiente y las investigaciones sobre el cambio climático.
Acerca del autor:
Rim Elijah tiene una doble titulación en Administración de empresas y Ciencias políticas por la Universidad de Estocolmo. Como Vicepresidenta de ventas en EOSDA, supervisa todos los aspectos del desarrollo y aplicación del modelo de negocio y el crecimiento a nivel global de la empresa. Ha conseguido establecer varias asociaciones estratégicas enfocadas en la sostenibilidad en África y Asia.
Artículos recientes

Guía De Transición De Sentinel Hub EO Browser A EOSDA LandViewer
Las alternativas a EO Browser son muchas y variadas. EOSDA LandViewer le resultará familiar, pero con funciones extra: imágenes satelitales recientes, un gran archivo de datos y análisis avanzados.

EOSDA Y Agribest: Impulsando La Agritech En México
En esta interesante entrevista, Agribest comparte cómo su colaboración con EOSDA está dando forma al futuro agrícola de México, centrándose en la rentabilidad, la sostenibilidad y la tecnología.

Mapa De Rendimiento Para La Agricultura De Precisión
¿Por qué dos campos anexos producen resultados tan diferentes? La cartografía y los mapas de rendimiento ayudan a explicar en qué zonas se desperdician los insumos y cómo gestionarlos adecuadamente.