A classificação de uso da terra e cobertura da terra (UTCT) é um tipo de dados geoespaciais em um formato visual que categoriza a superfície da Terra em classes distintas, como floresta, água, plantações e muito mais. A utilização de sensoriamento remoto e dados geoespaciais para detecção de mudanças na cobertura da terra ajuda a avaliar a dinâmica na maneira como a terra é usada ou avaliar como as mudanças climáticas alteram a superfície da Terra em regiões específicas. Também ajuda a criar soluções baseadas em dados em relação a infraestruturas, como onde construir estradas, novos edifícios ou fábricas.
As imagens de satélite fornecem dados abundantes não apenas no espectro visível (RGB), mas também em faixas multiespectrais que são imperceptíveis para os seres humanos. Uma imagem de satélite multiespectral é suficiente para distinguir, por exemplo, certas culturas umas das outras com maior precisão do que se olharmos para uma foto normal. No entanto, para executar com sucesso uma classificação UTCT, você precisaria treinar um modelo de rede neural personalizado.
Os clientes da EOS Data Analytics demonstram uma demanda crescente por tais modelos. Dê uma olhada nas formas como esses modelos são treinados com esta visão geral e três casos de uso na Bulgária, Nigéria e Brasil.
Por Que As Empresas Solicitam A Classificação Da Cobertura Da Terra
Se você é novo na análise geoespacial, pode estar se perguntando por que as empresas estão solicitando cada vez mais a classificação de UTCT. Você pode olhar para uma imagem de satélite RGB e identificar o que é o quê com seus próprios olhos. Por que eles optam por imagens rasterizadas codificadas por cores da floresta se já viram a floresta em RGB?
A resposta é – avaliação quantitativa. As empresas precisam colocar a dinâmica da mudança em números, caso contrário, não conseguirão gerenciar o uso da terra. Eles querem prever quanto de um produto final podem produzir e vender com base no rendimento da colheita, alocar o orçamento necessário e apresentar soluções relevantes de engenharia, logística, etc. Enquanto isso, a representação visual de uma classificação UTCT em cores simples em um mapa geográfico ajuda os humanos a compreender as informações sobre os resultados da classificação. Alguns padrões você só pode ver quando visualiza os dados e os analisa da perspectiva de um humano, misturando sua intuição, memórias e percepções individuais e padrões lógicos não lineares que até mesmo a máquina mais inteligente nunca teria adivinhado.
É essencial sempre ajustar a precisão dos algoritmos de mapeamento UTCT porque a cobertura da terra é um valor altamente flutuante – nunca permanece o mesmo. As estações mudam, os níveis de água vêm e vão, as chuvas caem e assim por diante. Portanto, uma rede neural precisa se ajustar continuamente a novas circunstâncias e suas conexões umas com as outras.
Por exemplo, se você está lidando com uma enchente de primavera em uma superfície plana, como saber para onde vai a água desta vez? É como derramar um copo d’água em uma mesa – a trajetória do resultado é compreensível, mas um pouco incerta, dependendo da textura e tamanho da sua mesa, a velocidade de virar o copo de cabeça para baixo, os objetos sobre ele, etc. Da mesma forma, o fluxo de inundação pode literalmente ir a qualquer lugar, mas tem algumas dependências que são quase impossíveis de prever com o cérebro humano porque há muitas variáveis em diferentes níveis de correlação. É aí que entra a IA.
A equipe de cientistas da EOSDA trabalha continuamente no treinamento de modelos de redes neurais para classificação da cobertura da terra. Para manter a máxima precisão, desenvolvemos um modelo de regressão personalizado totalmente conectado (MRTC). Vamos ver como funciona e revisar alguns exemplos proeminentes em que nosso algoritmo alcançou ótimos resultados.
Classificação Da Cobertura Da Terra: Como Fazemos
1. Coletando e pré-processando os dados: Primeiro, coletamos imagens de satélite e os dados reais correspondentes (como clima ou níveis de precipitação) para diferentes classes de cobertura da terra. Pré-processamos os dados construindo uma série temporal para classificação, segmentando imagens em patches,e codificando os rótulos da situação fática.
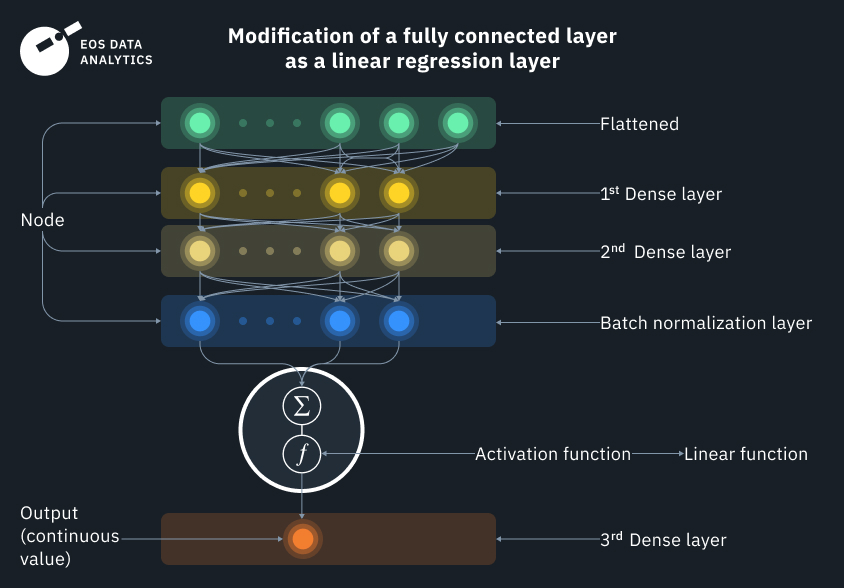
2. Projetando a arquitetura: neste estágio, codificamos um modelo de regressão personalizado totalmente conectado (MRTC) para cada classe, que é modificado em uma regressão linear na saída. Todos esses termos podem soar estranhos para você se você nunca lidou com redes neurais antes, mas, na verdade, eles são mais simples do que parecem. Por exemplo, totalmente conectado significa que todas as entradas e todos os nós (camadas) têm conexões entre si, enquanto a regressão linear mais simples pode ser descrita como uma equação linear na forma de interceptação de inclinação,
que todos nós estudamos na escola. Aqui, x é uma variável independente e y é uma variável dependente. Eles têm uma dependência linear, onde cada valor de y depende do valor de x.
Em uma rede neural, você pode pensar em dados de satélite (entrada) como x e y, e a própria função como um neurônio. Assim como os neurônios físicos, os neurônios funcionais só disparam se uma determinada condição for atendida.
Em nosso algoritmo, temos vários neurônios (funções) que estão todos conectados entre si. Na saída, obtemos uma função de ativação de regressão linear usando várias regressões logísticas (binárias) como entrada, o que é uma solução bastante interessante. O modelo tem que fazer muitas escolhas multivariadas antes de decidir sobre o resultado final. É como uma condição exagerada para cada pixel em que uma imagem de satélite se decompõe, se transforma e depois se recompõe como o BumbleBee.
Os dados de saída contínuos mostram a probabilidade da entrada inicial pertencer a uma determinada classe. Assim, primeiro obtemos a multiplicidade de valores possíveis, depois dividimos em intervalos que mostram uma medida da relação entre as variáveis de entrada. Finalmente, uma determinada classe é dada a um intervalo escolhido.
3. Dividindo do conjunto de dados: Dividimos o conjunto de dados pré-processado em conjuntos de treinamento, validação e teste usando uma proporção apropriada (por exemplo, 70% de treinamento, 15% de validação e 15% de teste). Também tentamos garantir que todos os conjuntos tenham uma representação balanceada de classes.
4. Treinando os modelos: treinamos cada MRTC separadamente no conjunto de treinamento, minimizando o Erro Quadrático Médio (EQM) entre as probabilidades previstas e os rótulos de verdade. Durante o treinamento, usamos algoritmos de otimização para atualizar os parâmetros do modelo iterativamente. Em seguida, regularizamos os modelos para evitar overfitting (aprendizado com ruído) empregando técnicas como dropout ou decaimento de peso.
5. Monitorando o desempenho da validação: acompanhamos o desempenho de cada MRTC no conjunto de validação durante o treinamento usando métricas de avaliação como R-quadrado ou erro médio absoluto (EMA). Ajustamos hiperparâmetros como taxa de aprendizado, tamanho do lote ou complexidade do modelo se precisarmos otimizar o desempenho. Geralmente, não há uma solução única para todos quando se trata desses parâmetros, por isso os ajustamos sempre.
6. Modelagem de conjunto: Combinamos previsões de MRTCs individuais para obter uma classificação final do tipo de cobertura da terra empregando métodos de conjunto.
7. Avaliando o desempenho do conjunto de teste: Avaliamos o desempenho geral de nosso algoritmo em dados de teste (anteriormente não vistos por um modelo) usando métricas como erro estatístico e matriz de confusão.
8. Ajuste fino e iteração: neste estágio, iteramos as etapas 2 a 7, refinando a arquitetura, os hiperparâmetros ou o método de conjunto para melhorar o desempenho da classificação.
9. Recortando o resultado final pelo quadro: Finalmente, estamos preparando as visualizações de saída em relação às coordenadas ADI (área de interesse) predefinidas.
Diferença Na Classificação: Comparação Entre EOSDA E Fontes De Referência
Comparamos nossos resultados de classificação com os dados abertos UTCT fornecidos por duas fontes de referência para validar a saída gerada por nosso modelo. Vamos chamá-los de Fonte 1 e Fonte 2.
A Fonte 1 oferece dados de 2017 a 2022, enquanto os dados da Fonte 2 vão de 2015 a 2019. Percebemos que os resultados da classificação UTCT de grandes empresas podem variar. Uma possível razão para essas discrepâncias na classificação da cobertura da terra são os diferentes métodos de agregação de classes empregados. Por exemplo, um provedor de dados pode classificar florestas como uma única classe, enquanto o modelo de outro provedor distingue entre florestas esparsas e densas. Consequentemente, classes que representam áreas relativamente pequenas dentro do território de interesse podem apresentar diferenças significativas, conforme mostrado na visualização abaixo. No entanto, isso não se aplica a mudanças ano a ano dentro da mesma classe.
Nas visualizações e gráficos, você pode ver o território da cidade de Varna, na Bulgária. Podemos dizer que as classes não permanecem as mesmas, ao contrário, flutuam um pouco de ano para ano. Os gráficos de barras abaixo mostram uma análise mais detalhada de 2019, pois é comum a ambas as fontes de referência.
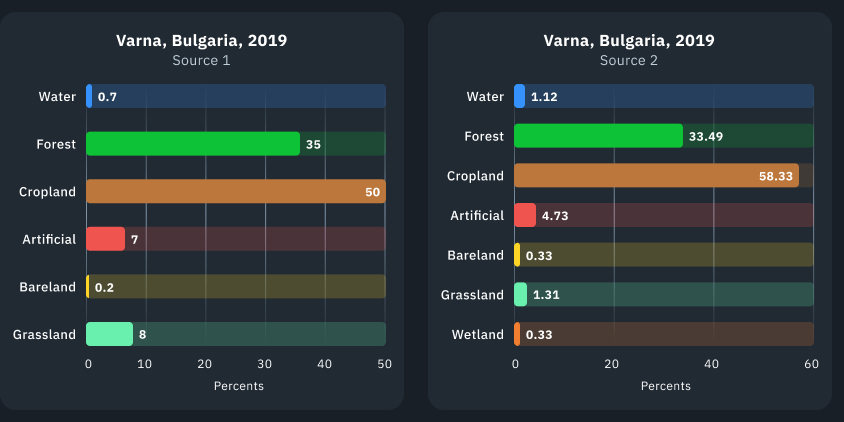
A visualização e o gráfico de barras a seguir mostram as estatísticas recebidas do modelo EOSDA. Como você pode ver, os resultados da classificação são um pouco diferentes.
Um exemplo notável: a classificação UTCT do EOS Data Analytics fornece a classe Grassland para áreas de pastagem e áreas com presença de arbustos subdimensionados, enquanto a classificação da Fonte 2 demonstra que esses valores estão em classes completamente diferentes. Por esse motivo, a porcentagem de classes pode ser diferente.
Após a comparação, concluímos que os resultados da classificação da cobertura da terra de diferentes modelos podem variar. Isso pode ser devido ao fato de que objetos que parecem ser visualmente semelhantes, mas de natureza diferente, podem ser classificados como uma classe ou outra, dependendo do algoritmo, dados de entrada, processo de treinamento, etc. Para avaliar o nível de precisão com o nível de precisão mais alto, precisaríamos analisar o caso de uso específico e os dados de validação de fundamentos.

Exemplos De Classificação Da Cobertura Da Terra Pela EOSDA
Como você pode ver na comparação acima, os cientistas da EOSDA conseguiram atingir um alto nível de detalhes em nosso algoritmo UTCT. Em essência, o fator que mais poderia ter contribuído foi o uso de curtos períodos de dados de séries temporais de satélite. Essa abordagem também nos permite obter uma visão aguçada das classes identificadas. Embora, devemos admitir que os dados de entrada também devem ser suficientes.
Para validação adicional de nosso modelo em várias paisagens e condições climáticas, nós o treinamos com dados de algumas regiões diferentes. Dê uma olhada nos exemplos abaixo para ver os resultados do treinamento.
Região Nº 1: Bulgária, 2021
Vamos fechar os resultados da classificação UTCT obtidos pelo modelo EOS Data Analytics na Bulgária. Aqui podemos ver uma identificação muito precisa das classes de floresta, água e terras agrícolas. Vale a pena mencionar, que o último tem dependências estreitas entre o número de imagens de entrada obtidas, as flutuações sazonais e o resultado de saída.
Como podemos ver no resultado de saída, os cientistas da EOSDA treinaram o modelo com um número e qualidade suficientes de dados de entrada. A classe bareland de cor amarela inclui uma fixação detalhada da infraestrutura de pavimento local. O modelo também identificou objetos artificiais.

Região Nº 2: Nigéria, 2021
Este resultado do treinamento mostra que o modelo identificou as terras secas da Nigéria como uma classe de terra nua. No entanto, uma pequena quantidade de água e pastagens também é identificada com detalhes precisos. Mesmo territórios menores de uma classe de zonas úmidas mostram inundações sazonais (ou a falta delas, o que pode significar uma seca).
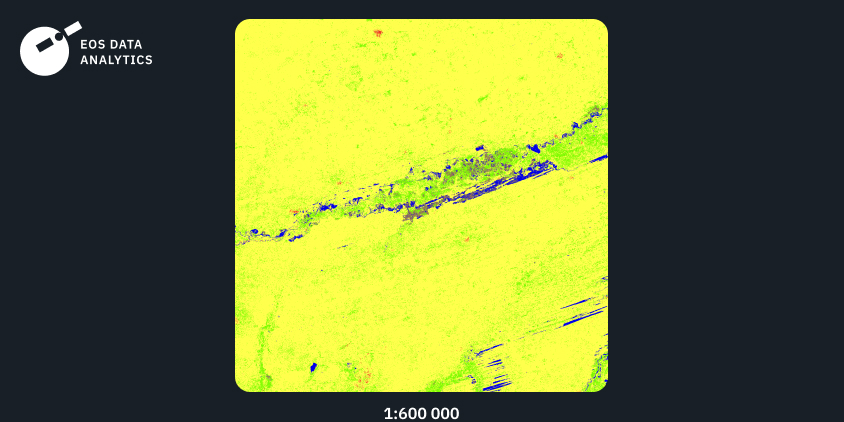
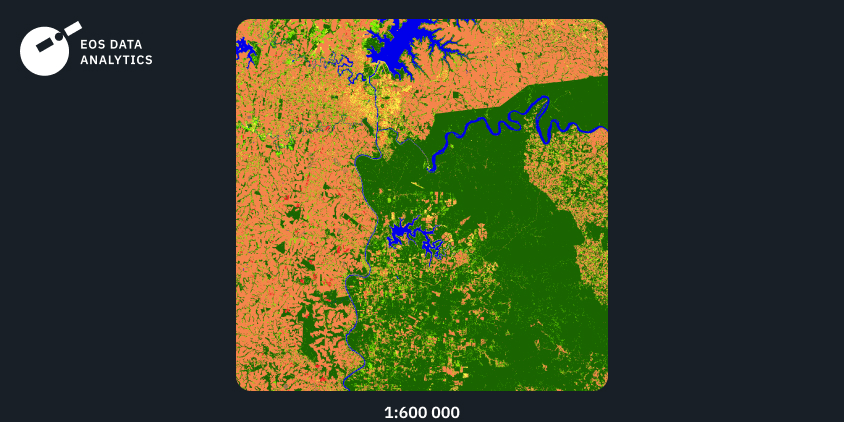
Região Nº3: América Do Sul, 2021
O terceiro exemplo mostra a saída do nosso modelo treinado nos dados de entrada da América do Sul. Novamente podemos ver um alto nível de detalhes combinado com transições suaves entre as classes. Enquanto a classe floresta é predominante na ADI dada, a classe pastagem é precisamente diferenciada da classe floresta.
Considerações Finais
As empresas em vários domínios podem aproveitar nossos modelos para obter insights mais profundos sobre os padrões de uso da terra, otimizar a alocação de recursos e tomar decisões informadas para aumentar a lucratividade. De uma perspectiva mais ampla, ao obter uma classificação centímetro a centímetro da Cobertura da terra dos territórios de interesse, as comunidades podem tomar as medidas necessárias para salvar o meio ambiente e construir infraestruturas sustentáveis.
Cada modelo treinado personalizado na EOSDA é baseado em um algoritmo supervisionado por humanos, é por isso que conseguimos alcançar uma qualidade tão impressionante dos resultados de saída. Como ponto de partida, já treinamos nosso modelo UTCT em dados de diferentes geografias, como você pode ver neste artigo. Ao refinar ainda mais a arquitetura e os parâmetros de dados em cada caso de forma iterativa, nossos cientistas são capazes de obter um erro estatístico significativamente menor, ou seja, aumentar a precisão da classificação.
Outro benefício é que quanto mais modelos UTCT personalizados nossos cientistas supervisionarem, mais contexto eles terão em mãos. Como resultado, eles podem construir modelos mais inteligentes do que alguém sem experiência neste campo. Estamos continuamente obtendo informações valiosas sobre como o monitoramento por satélite contribui para a gestão eficiente dos recursos terrestres, juntamente com os esforços de conservação ambiental e pesquisa sobre mudanças climáticas.
Precisa de uma solução personalizada para os objetivos da sua empresa? Agende uma conversa com nossa equipe e descubra como podemos ajudar.


Transforme dados avançados de satélite em soluções que fortalecem o seu negócio.

Mais notícias

EOSDA Fornece Dados Ao Serviço Florestal De Nebraska
Kun-Yuan Lee, especialista em GIS de Conservação Florestal no Serviço Florestal de Nebraska, conseguiu monitorar remotamente o extenso território florestal com a ajuda do EOSDA LandViewer.

Agribest Confirmou Pesquisa Com Sensoriamento Remoto
O EOSDA Crop Monitoring está ajudando a Agribest a confirmar seus dados, demonstrar os efeitos das pesquisas de seus produtos para os clientes e impulsionar a inovação na agricultura mexicana.

Biomassa No Brasil Calculada Com Sensoriamento Remoto
Cientistas brasileiros participaram do EOSDA Academic Outreach e calcularam a biomassa da terra com análises de imagens de satélite, para prever a produtividade e aplicar fertilizantes em pastagens.