Класифікація Ґрунтово-Рослинного Покриву Разом З EOSDA
Класифікація землекористування та ґрунтово-рослинного покриву – це тип геопросторових даних у візуальному форматі, який класифікує поверхню Землі за окремими класами, такими як ліс, вода, сільськогосподарські культури тощо. Використання даних дистанційного зондування та геопросторових даних для виявлення змін ґрунтово-рослинного покриву дає змогу оцінити динаміку використання земель або те, як кліматична криза змінює поверхню Землі в певних регіонах. Це також допомагає розробляти рішення, засновані на даних, для інфраструктурних об’єктів, наприклад, для визначення місць будівництва нових доріг, будівель або заводів.
Супутникові знімки містять велику кількість даних не тільки у видимому діапазоні (RGB), а й в інших ділянках електромагнітного спектра, які не розрізняє людське око. Аналіз мультиспектрального супутникового зображення дає змогу більш точно відрізнити один тип сільськогосподарських культур від іншого порівняно з поглядом на звичайну фотографію. Однак для успішної класифікації ґрунтово-рослинного покриву необхідно навчити спеціальну модель нейронної мережі.
Клієнти EOS Data Analytics є підтвердженням того, що попит на такі моделі зростає. У цьому матеріалі ми розповімо про те, як відбувається навчання цих моделей на прикладі трьох випадків їх застосування в Болгарії, Нігерії та Бразилії.
Чому Компанії Замовляють Класифікацію Ґрунтово-Рослинного Покриву
Якщо ви новачок у галузі геопросторового аналізу, вас може дивувати той факт, що компанії все частіше замовляють класифікацію ґрунтово-рослинного покриву. Адже можна подивитися на супутниковий RGB-знімок і визначити географічні об’єкти неозброєним оком. Навіщо їм растрові зображення лісу з кольоровим маркуванням, якщо вони й без цього бачать ліс на знімку в природному кольорі?
Відповідь – задля кількісної оцінки. Підприємствам необхідно відобразити динаміку змін у цифрах, інакше вони не зможуть управляти земельними ресурсами. Вони прагнуть передбачити обсяг кінцевого продукту, який зможуть виробити й продати на основі врожайності, розподілити необхідний бюджет, запропонувати відповідні технічні рішення, логістику тощо. А візуальне представлення класифікації ґрунтово-рослинного покриву у вигляді простих кольорів на географічній карті допомагає людині осмислити її результати. Деякі закономірності можна виявити тільки візуалізувавши й проаналізувавши дані з позиції людини, додавши інтуїцію, індивідуальні спогади та сприйняття, а також нелінійні логічні закономірності, про які ніколи не здогадався б навіть найрозумніший комп’ютер.
Дуже важливо постійно налаштовувати точність алгоритмів картування, оскільки ґрунтово-рослинний покрив – вкрай мінлива величина, яка регулярно зазнає змін. Змінюються сезони, підвищується і знижується рівень води, випадають дощі тощо. Тому нейронна мережа повинна раз за разом підлаштовуватися під нові обставини та їхні зв’язки між собою.
Наприклад, якщо ви маєте справу з весняним паводком на плоскій місцевості, то як дізнатися, куди вода потече цього разу? Це те саме, що пролити склянку води на стіл: траєкторія руху загалом зрозуміла, але дещо невизначена, залежить від фактури й розміру столу, швидкості перевертання склянки, предметів, що знаходяться на ньому тощо. Аналогічним чином, потік води може буквально хлинути куди завгодно, але при цьому є певні залежності, які людський мозок майже не в змозі передбачити, адже існує дуже багато змінних з різним ступенем кореляції. Ось тут на допомогу і приходить штучний інтелект.
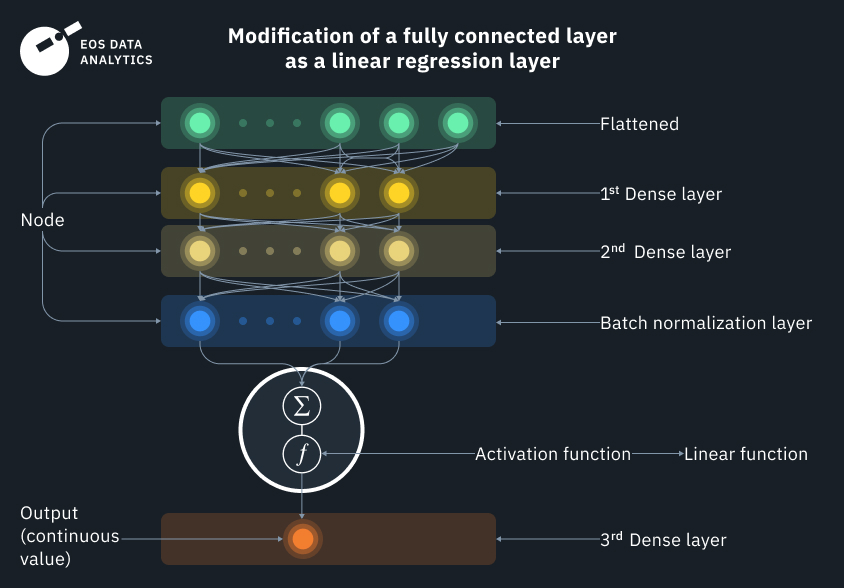
Команда науковців EOSDA постійно працює над навчанням нейромережевих моделей для класифікації ґрунтово-рослинного покриву. Для забезпечення максимальної точності ми розробили власну повнозв’язну регресійну модель (Fully Connected Regression Model, FCRM). Дізнаємося, як вона працює, і розглянемо кілька показових прикладів, у яких наш алгоритм показав чудові результати.
Класифікація Ґрунтово-Рослинного Покриву: Як Ми Це Робимо
1. Збір і попереднє опрацювання даних. Спочатку ми збираємо супутникові зображення та відповідні наземні дані (наприклад, погоду або рівень опадів) для різних класів ґрунтово-рослинного покриву. Попереднє опрацювання полягає в побудові часових рядів для класифікації, сегментації зображень на ділянки та присвоєнні міток наземним даним.
2. Побудова архітектури. На цьому етапі ми програмуємо індивідуальну повнозв’язну регресійну модель для кожного класу, яка на виході перетворюється на лінійну регресію. Якщо ви ніколи не стикалися з нейронними мережами, всі ці терміни можуть здатися незрозумілими, але насправді вони простіші, ніж здаються. Наприклад, “повнозв’язна” означає, що всі входи та вузли (шари) пов’язані один з одним, а найпростішу лінійну регресію можна описати як лінійне рівняння з кутовим коефіцієнтом,
яке кожен з нас вивчав у школі. Тут x – незалежна змінна, а y – залежна змінна. Вони мають лінійну залежність, де кожне значення y залежить від значення x.
У нейронній мережі супутникові (вхідні) дані можна представити як x і y, а саму функцію – як нейрон. Подібно до нейронів в організмі людини, нейрони функції спрацьовують тільки при виконанні певної умови.
Наш алгоритм містить у собі кілька пов’язаних між собою нейронів (функцій). На виході ми отримуємо функцію активації лінійної регресії, яка приймає на вхід безліч логістичних (бінарних) регресій, що саме по собі є досить цікавим рішенням. Модель повинна зробити велику кількість багатоваріантних виборів, перш ніж прийняти остаточне рішення. Це схоже на розгалужений ланцюг умов “якщо” для кожного пікселя, на які розбивається супутниковий знімок, а потім перетворюється і знову збирається докупи, як робот-трансформер.
Безперервні вихідні дані відображають імовірність належності початкових вхідних даних до певного класу. Отже, спочатку ми отримуємо безліч можливих значень, а потім розбиваємо її на діапазони, які демонструють ступінь зв’язку між вхідними змінними. Нарешті, обраному діапазону присвоюється певний клас.
3. Розбиття набору даних. Ми ділимо попередньо оброблений набір даних на навчальний, валідаційний і тестовий набори, використовуючи відповідне співвідношення (наприклад, 70% навчальних, 15% валідаційних і 15% тестових даних). Ми також намагаємося зробити так, щоб усі класи були рівномірно представлені в кожному наборі.
4. Навчання моделей. Ми навчаємо кожну повнозв’язну регресійну модель окремо на навчальному наборі, мінімізуючи середню квадратичну помилку (MSE) між передбаченими ймовірностями й мітками наземних даних. У процесі навчання ми використовуємо алгоритми оптимізації для ітеративного оновлення параметрів моделі. Потім ми регуляризуємо моделі для запобігання перенавчання (навчання на шумах) за допомогою таких технік, як проріджування або ослаблення ваги.
5. Моніторинг ефективності валідації. Протягом навчання ми відстежуємо ефективність роботи кожної моделі на контрольній вибірці за допомогою таких оцінювальних показників, як R-квадрат або середня абсолютна помилка (MAE). У разі необхідності ми коригуємо такі гіперпараметри, як швидкість навчання, розмір вибірки або складність моделі. Як правило, універсального рішення щодо цих параметрів не існує, тому щоразу ми виконуємо їхнє тонке налаштування.
6. Збірка ансамблю. Застосовуючи ансамблеві методи, ми комбінуємо прогнози окремих моделей для отримання підсумкової класифікації типів ґрунтово-рослинного покриву.
7. Оцінка ефективності тестового набору. Ми оцінюємо загальну дієздатність нашого алгоритму на тестових даних (які модель ще не “бачила”), використовуючи такі метрики, як статистична помилка і матриця невідповідностей.
8. Тонке налаштування та ітерації. На цьому етапі ми повторюємо кроки 2-7, удосконалюючи архітектуру, гіперпараметри або ансамблевий метод для підвищення ефективності класифікації.
9. Обрізка підсумкового результату. Нарешті, ми готуємо вихідну візуалізацію відповідно до заданих координат області інтересу (AOI).
Різниця Класифікацій: Порівняння EOSDA І Відкритих Джерел
Для валідації результатів алгоритму ми порівняли наші результати з відкритими даними щодо класифікації землекористування та ґрунтово-рослинного покриву з двох різних джерел. Назвемо їх Джерело 1 і Джерело 2.
Джерело 1 містить дані за період з 2017 по 2022 рік, а Джерело 2 – за період з 2015 по 2019 рік. Ми помітили, що результати класифікації, отримані великими компаніями, можуть різнитися. Однією з можливих причин таких розбіжностей у класифікації ґрунтово-рослинного покриву є різні методи агрегування класів. Наприклад, один постачальник даних може класифікувати ліси як єдиний клас, тоді як модель іншого постачальника виокремлює розріджені та густі ліси. У результаті класи, що представляють відносно невеликі ділянки на досліджуваній території, можуть мати істотні відмінності, як показано на графіках нижче. Однак це не стосується міжрічних змін у межах одного і того ж класу.
Далі представлена візуалізація даних для території міста Варна, Болгарія. Як правило, класи – непостійна величина, яка незначною мірою коливається з року в рік. Нижче наведено більш детальну розбивку за 2019 рік, оскільки цей період є спільним для обох відкритих джерел.
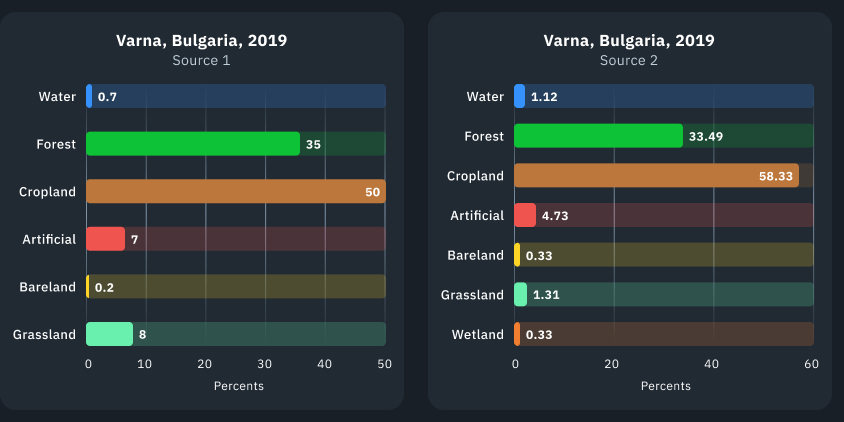
Діаграма та ілюстрація, що наведені нижче, містять статистику, отриману за допомогою моделі EOSDA. Як видно, результати класифікації дещо відрізняються.
Яскравий приклад: класифікація ґрунтово-рослинного покриву EOS Data Analytics передбачає клас “трав’яний покрив” (grassland) як для пасовищ, так і для ділянок, вкритих низькорослими чагарниками, проте у класифікації Джерела 2 ці значення відносяться до абсолютно різних класів. З цієї причини процентне співвідношення класів може відрізнятися.
Здійснивши порівняння, ми дійшли висновку, що результати класифікації ґрунтово-рослинного покриву, отримані за допомогою різних моделей, можуть відрізнятися. Це може статися через те, що візуально схожі, але різні за своєю природою об’єкти можуть бути віднесені до того чи іншого класу залежно від алгоритму, вихідних даних, процесу навчання тощо. Для того щоб правильно оцінити рівень точності, необхідно проаналізувати конкретний випадок використання і наземні дані, що застосовуються для валідації.

Приклади Класифікації Ґрунтово-Рослинного Покриву На Основі Алгоритму EOSDA
З наведеного вище порівняння видно, що вченим EOSDA вдалося досягти високого рівня деталізації алгоритму класифікації ґрунтово-рослинного покриву. Ймовірно, вирішальним фактором стало використання коротких періодів часових рядів супутникових даних. Такий підхід також дає змогу отримати чіткіше уявлення про виявлені класи. Хоча слід визнати, що й вихідні дані мають бути представлені в достатній кількості.
Для подальшої валідації нашої моделі на різних ландшафтах і кліматичних умовах ми використовували для її навчання дані з кількох різних регіонів. Результати можна побачити на прикладах нижче.
Регіон №1: Болгарія, 2021
Розгляньмо результати класифікації землекористування та ґрунтово-рослинного покриву Болгарії, які були отримані за допомогою моделі EOS Data Analytics. Тут ми бачимо дуже чітке виділення класів лісів (forest), водойм (water) і сільськогосподарських угідь (cropland). Варто зазначити, що у випадку з останнім класом спостерігається суттєва залежність між кількістю отриманих вхідних зображень, сезонними коливаннями та результатом.
Кінцеве зображення свідчить про те, що для навчання моделі науковці EOSDA використали якісні дані в достатній кількості. Клас “землі, позбавлені рослинності” (bareland), представлений жовтим кольором, містить детальну фіксацію місцевої дорожньої інфраструктури. Модель також визначила штучні об’єкти (artificial).

Регіон №2: Нігерія, 2021
З цього результату навчання видно, що модель віднесла посушливі землі Нігерії до класу земель, позбавлених рослинності. Проте їй також вдалося з великою точністю визначити нечисленні водойми та ділянки трав’яного покриву. Більш дрібні території класу водно-болотних угідь (wetland) демонструють сезонні паводки (або їх відсутність, що може свідчити про посуху).
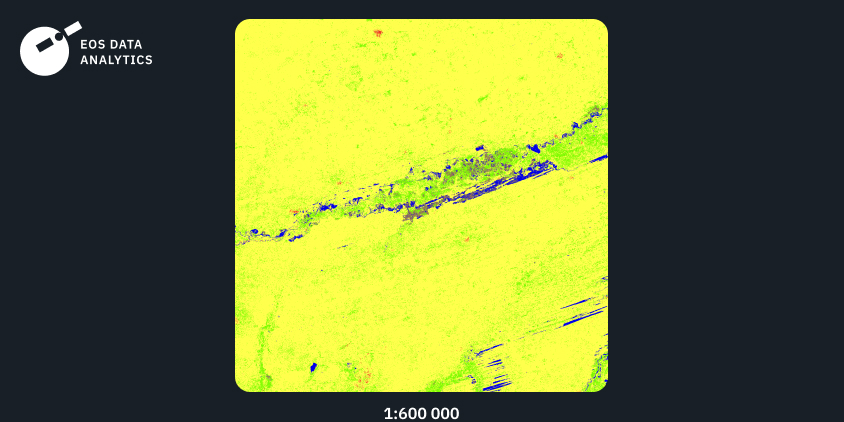
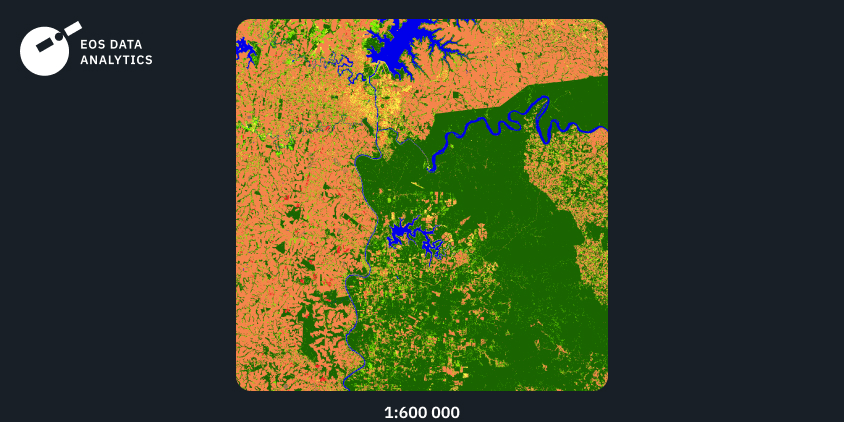
Регіон №3: Південна Америка, 2021
У третьому прикладі наведено результат навчання нашої моделі на вихідних даних з Південної Америки. Тут ми знов спостерігаємо високу деталізацію в поєднанні з плавними переходами між класами. Попри те, що в даній AOI переважають ліси, на зображенні присутній чіткий поділ між класом трав’яного покриву і класом лісів.
Кінцеві Думки
Підприємства різних галузей можуть застосовувати наші моделі для отримання докладнішої інформації про структуру землекористування, оптимізації розподілу ресурсів і прийняття обґрунтованих рішень для збільшення прибутковості. З більш глобальної точки зору, отримавши класифікацію ґрунтово-рослинного покриву досліджуваних територій з точністю до сантиметра, місцеве населення може вживати необхідних заходів для збереження довкілля та побудови стійкої інфраструктури.
В основі кожної індивідуально навченої моделі EOSDA лежить алгоритм, контрольований людиною, саме тому нам і вдається досягти настільки якісних результатів. Відправною точкою стало навчання нашої моделі класифікації землекористування та ґрунтово-рослинного покриву на даних по різних географічних регіонах, про що ми докладно розповіли в цій статті. Завдяки ітеративному доопрацюванню архітектури та параметрів даних у кожному конкретному випадку нашим вченим вдається домогтися значного зниження статистичної помилки, тобто підвищити точність класифікації.
Чим більше індивідуальних моделей класифікації навчають наші науковці, тим більше контексту в їхньому розпорядженні. І це є ще однією перевагою, завдяки якій вони можуть створювати “розумніші” моделі на відміну від тих, хто не має досвіду роботи в цій галузі. Ми постійно отримуємо цінні відомості про те, як супутниковий моніторинг сприяє ефективному управлінню земельними ресурсами, збереженню довкілля та дослідженню зміни клімату.
Про автора:
Рим Елайджa має подвійний диплом Стокгольмського університету з бізнес-адміністрування та політології. Як віце-президентка з продажів в EOSDA, вона контролює всі аспекти розробки та впровадження бізнес-моделі, а також розширення присутності компанії на глобальному ринку. Вона успішно створила низку стратегічних партнерств з акцентом на сталі рішення в Африці та Азії.
Oстанні статті

Огляд Ринку Та Тенденції В AgriTech На 2024-2030 Роки
Артем Анісімов, генеральний директор EOSDA, представляє аналітичний white paper про поточні тенденції сільського господарства до 2030 року та розповідає цікаві клієнтам компанії факти про agritech.

Нор-Ест Агро Визначає Продуктивність Через Супутники
Українська Нор-Ест Агро використовує вегетаційні індекси та погодну аналітику в EOSDA Crop Monitoring для визначення ефективності комплексних рішень на полях партнерів.

Пероноспороз: Як Розпізнати, Запобігти Та Боротися
Пероноспороз — агресивна хвороба, що загрожує врожаям. Вчасне виявлення і продумана профілактика допоможуть зберегти посіви та підвищити економічну стабільність агробізнесу.